需求
可伸缩布局技术产生已久,但对其利用非常地少,至今只能在一些移动站点上隐约看到它的身影。这不仅仅因为其只能针对较新的浏览器,而且其 API 也较为复杂。
现今的针对多屏设备的站点依然强依赖于媒体查询。其后果是会产生大量冗余的 CSS 代码与百分比宽高定义,增加维护难度。相比之下,可伸缩布局技术提供了一次编写代码适配多种屏幕尺寸的能力。
例如,我们想要构建一个下面这样的横排布局:
|-----|-----|----------|
| 1 | 1 | 2 |
|-----|-----|----------|
HTML 代码为:
<div class="wrapper">
<div class="item"></div>
<div class="item"></div>
<div class="item"></div>
</div>
要求在不同的屏幕宽度下依旧保持这种比例关系:1:1:2。我们可能会这样编写css代码:
.wrapper{width:100%;}
.item{float:left;width:25%;}
.item:last-child{width:50%;}
各个 item 子元素的宽度比例需要小心的维护,如果需要新增加一个元素,比例值需要重新计算,你肯定不想遇到一个不能整除的除法计算,比如100/6。
上面的例子中,各个子元素的宽度和等于父元素,如果期望之间存在差值怎么办,比如每个子元素存在一个固定的 1px 右边距,那么宽度该如何定义?
使用 calc 是一个方法:
.wrapper{width:100%;}
.item{float:left;width:calc(25% - 1px);margin-right:1px;}
.item:last-child{width:50%;}
只可惜这种方式依然需要清醒地人工计算,何况 calc 本身支持并不好。
使用 ::after 也是一种方法,不过显然会带来更多问题。
可伸缩布局(flex)提供了相当简单地分配剩余空间的方法,并且书写很傻瓜————你不需要关心最终是如何计算的,总之它能很清晰地实现你想要的比例布局:
.wrapper{width:100%;display:flex;}
.item{flex:1;margin-right:1px;}
.item:last-child{flex:2;margin-right:0;}
对,你只需要告诉浏览器你想要的比例,多出来的 margin,padding,border都不必额外考虑。
语法
flex 作用于内外两级元素,外层称之为“容器”,内层称之为“元素”。需要将容器设置:
display:flex;/*块级元素*/
/*或*/
display:inline-flex;/*内联元素*/
与之前的 display:inline 和 display:block 没什么分别。经过这样的设置,其直接子元素即刻拥有可伸缩能力。要定义子元素的占比,设置:
flex:1;
/*或*/
flex:2;
系统会根据各个元素的占比自动计算其真实尺寸。值得一提的是,拥有 flex 设置的元素仅均分剩余空间的大小————固定尺寸的子元素不受影响。以上面的 HTML 结构为例,书写 CSS:
.wrapper{width:200px;display:flex;}
.item:first-child{width:50px;}
.item:nth-child(1){flex}
.item:last-child{flex:2;}
那么产生的布局是:
|-----|-----|----------|
| 50px| 50px| 100px |
|-----|-----|----------|
其中第一个元素固定为 50px,第二个元素占剩余的 1/3,即(200-50)/3=50px,最后一个元素占2/3,即 100px。
flex 拥有主轴和侧轴的概念,可以简单地理解为 XY 坐标系。默认横向为 X 轴,纵向为 Y 轴。可以通过 flex-direction 作用于容器来改变设置。在主轴上子元素的对齐由 justify-content 控制,侧轴子元素对齐由 align-items 控制,同时还可以控制元素显示顺序的 order,相关具体意义及备选值可查看 W3C 草案。
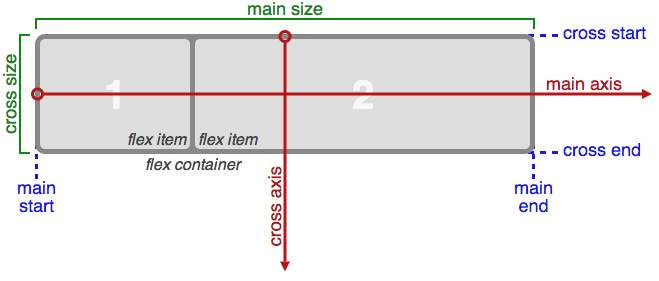
很不幸,flex 语法目前仍然处于草案阶段,并且经历了一次 box 旧语法的废弃————上面例子中的语法是最新的写法,从2009年开始各浏览器厂商陆续实现了一种现在被废弃的 box 语法,我们称之为老语法。更糟糕的是,微软的 IE10(包括桌面端和移动端)浏览器实现了一种介于新语法和旧语法之间的中间语法。下面的表格列举了这三种语法的API:
|
含义 |
新语法(-webkit- -moz-) |
老语法(-webkit- -moz-) |
IE10语法 |
| 1 |
弹性容器定义 |
display : flex/inline-flex |
display : box/inline-box |
display : -ms-flexbox |
| 2 |
子元素排列方式 |
flex-direction : row/ column-row/column/column-reverse |
box-orient : horizontal/vertical/inline-axis/block-axis/inherit |
-ms-flex-direction : row/column/row-reverse/column-reverse/inherit |
| 3 |
主轴子元素对齐 |
justify-content : flex-start/ flex-end/center/space-around/space-between |
box-pack : start/end/center/justify |
-ms-flex-pack : start/end/center/justify |
| 4 |
侧轴子元素分布 |
align-content : flex-start/ flex-end/center/space- around/space-between |
NOT SUPPORTED |
-ms-flex-line-pack: start/end/center/justify/distribute/stretch |
| 5 |
侧轴方向子元素对齐 |
align-items : flex-start/flex-end/center/stretch |
box-align : start/end /center/baseline/stretch |
-ms-flex-align : start/end/center/baseline/stretch |
| 6 |
弹性子元素伸缩值 |
flex : [positive-flex] [negative-flex] [preferred-size] |
box-flex : [positive-flex] |
-ms-flex : [positive-flex] [negative-flex] [preferred-size] |
| 7 |
子元素排列顺序 |
order : 1 |
box-ordinal-group : 1 (positive) |
-ms-flex-order : 1 |
| 8 |
在子元素中覆盖父元素定义的第5项 |
align-self : flex-start/flex- end/center/stretch |
NOT SUPPORTED |
-ms-flex-item-align : auto/start/end/center/baseline/stretch |
| 9 |
换行 |
flex-wrap : wrap/no-wrap/wrap-reverse |
NOT SUPPORTED |
-ms-flex-wrap : none/wrap/wrap-reverse |
需要指出的是新语法支持多行模式,老语法并不支持。
浏览器支持
Chrome,Safari,Opera,Firefox,IE10+,Android对可伸缩布局进行了支持,其中一些版本仅支持老语法,而另一些同时支持两种语法,查看这里。
因此似乎针对 iOS , Android 和 Windows Phone 8 移动设备开发的网站更适合应用 flex 技术,因为这些平台的浏览器都支持其中至少一种语法。针对 PC 你需要一种优雅的降级。
我做了一些针对不同语法的测试,在这里。
总结有几点需要注意:
- 针对 webkit 编程,需要兼容老语法,目前大多数使用 webkit 的浏览器都还不支持新的语法;
- 仅在横向方向上应用
flex,垂直放向上可以看见老语法在分配高度比例时存在问题;
- 如果子元素的内容区大小不同时,老语法会引起子元素的不均匀分配,即使子元素能够容纳其内容,这个时候,只要为每个子元素设定
width:100%即可,新语法和IE10在这方面没有问题,即使子元素的内容区溢出。opera(presto)在这个问题上处于中间状态,即内容区不溢出,子元素按照预订比例分配,如果溢出,子元素将会被撑大;
总结
flex 在针对现在浏览器编程的环境中是一个很方便的工具,IE11 和 Firefox 现在已经实现了无前缀的语法,相信 webkit 也会很快完成转换,届时新语法就会成熟,但老版本的 webkit 仍在存在很大的市场,因此在书写可伸缩 CSS 代码时仍然要兼容老语法,这会限制 flex 的应用。相对于普通的百分比计算方法,老语法提供的功能仍然足够日常使用。
另外,可以使用 autoprefixer 来自动屏蔽这三个版本之间的差异。
参考