同构场景下的复杂前端构建
提到 Web 前端工程化,构建,或者称为“编译”,是其中最重要的构成部分。由于出道比较晚,我在毕业后的第一家公司就职时就不得不掌握一定的构建知识和技能。当时我们使用的构建工具,使用 python 语言编写,主要能对 JavaScript 进行 AMD 规范的合并和压缩,对 CSS 进行合并压缩,以及增添各种时间戳。由于工具没有扩展功能,因此构建流程的固定的,如有必要,需要对工具进行升级,柔韧性并不好,好在当时的业务复杂度也并不高。
当时接手的一个腾讯的产品,其构建工具使用了包括 Shell、PHP、Ant 内的多种技术,非常繁杂,而且其重要构成部分 Ant 的任务扩展需要 Java 编写,成本并不低,也刚刚好也并没有额外的扩展需求,因此也就一直使用下去了。
不过伴随着 NodeJS 的发展,2013 年,grunt 已经开始出现,2014 年,gulp 也出现了。它们的适当使用都能更好地完成构建工作。
Webpack 虽然也在同时期发展,但直到近两年才被广泛应用。同时,在百度,FIS 也支撑着许多公司级的产品。
业务架构决定了选用何种构建工具,甚至是否需要像 Ember 一样自建工具。缺失场景冒然地比较它们是不合理不明智的,因为显然它们并非替代关系,只不过相互之间有些重合。
现在来看一个同构设计的复杂前端工程,它有以下特殊需求:
- 一份使用 ES2015 语法编写的 JavaScript 既需要编译成 CommonJS 格式运行在 Server 端,又需要编译成 AMD 格式,压缩合并运行在浏览器端;
- 为简便起见,使用 NPM 发布的前端 JavaScript Library 也允许编译到前端运行,包括所有依赖;
- HTML 模板既可能作为 Server 端的运行时模板,也可能被浏览器加载作为前端模板;
- 未被处理的文件需要原封不动拷贝至配置的对应目录中
先来看 FIS,这是一款有一定集成度的工具,即无需任何配置和插件都可以完成一定的构建任务。
来看其构建思路:
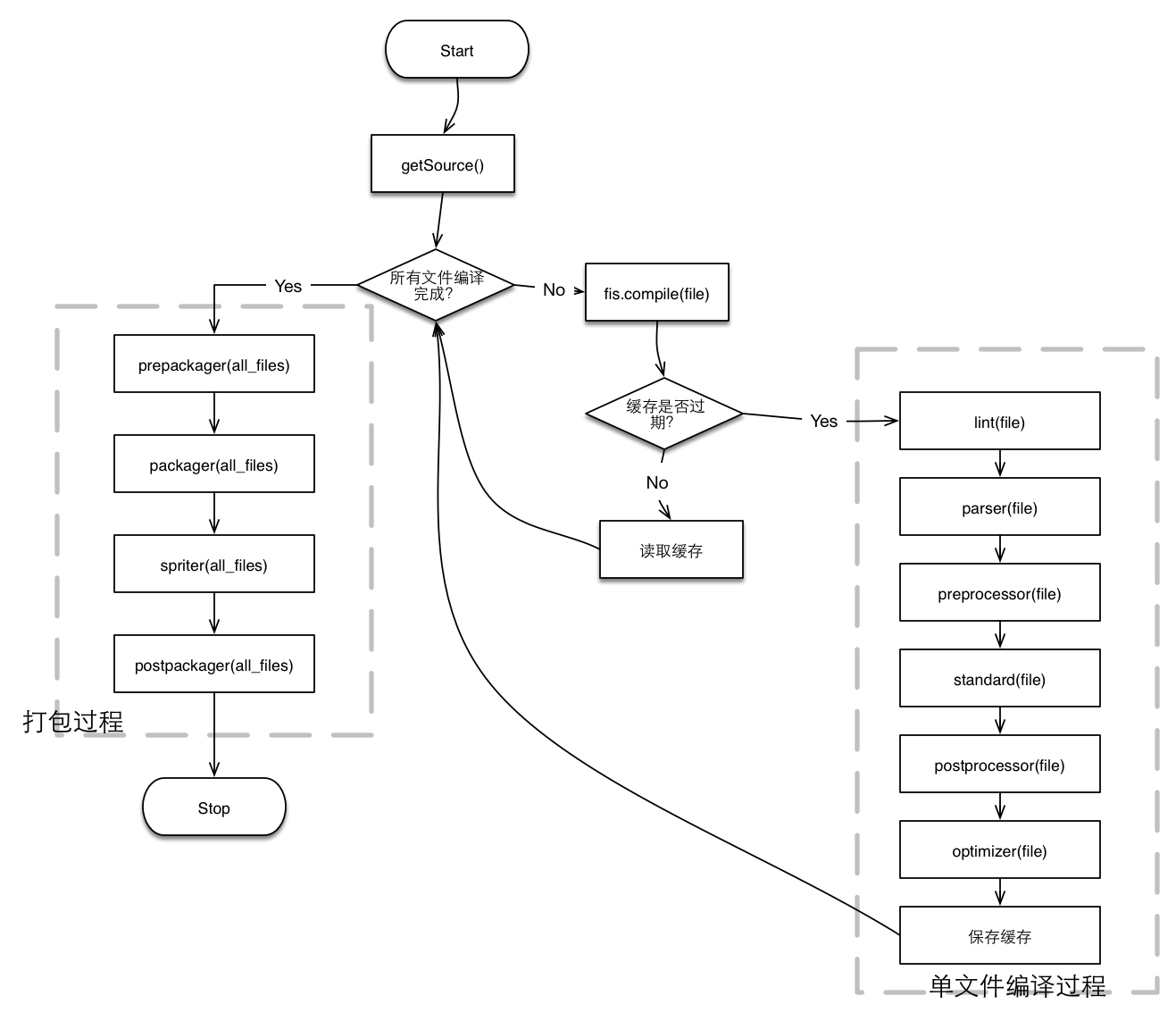
FIS 定义了几个主要编译阶段,每个阶段可以插入更多的扩展。在编译期,FIS 会遍历所有项目下的文件,对不同的文件采取不同的转换策略,最终都会再次写在磁盘的目的目录中。这样的好处是不会遗漏任何文件,比如新增文件类型,即使不做任何处理,都会出现在目的目录中。缺点是,一个源文件就只能有一个输出文件。在同构项目中,常常一个文件有两个甚至更多的输出,做到这一点,FIS 比较困难,但能做到,只要多次读取一份源文件,但这在配置上不够直观。
再来看 Webpack,它天生支持编译 NPM module,对于 browserify 式的打包非常方便。但 Webpack 至少需要一个 entry,即入口,因为它需要知道从哪开始分析依赖。无论从哪里看,Webpack 对于那种单页应用都更友好一些,在复杂的工程中,页面不可能仅有一个,一个页面中的 JavaScript 运行入口也可能不止一个,同时,将一个源文件编译成多个也几乎无法支持。这使得 Webpack 的应用场景比较狭隘。
Grunt 与 Gulp 集成化最低,也最灵活,通过配合插件,可以完成任意任务。相比之下,Gulp 基于流的处理,会比 Grunt 基于文件的处理来说更易控制,处理也更快。两者都是基于文件选择器的,因此对于没有选择到的文件,必然会遗漏。同时,对于不同选择器选择到的相同文件,也会读取不止一次。
基于以上考虑,对于更复杂的要求更高的同构项目,单单是使用现有的构建工具,要么不能完成任务,要么实现起来非常 tricky。重新审视构建这件事,其实要做的事情非常纯粹——读取文件,将文件内容按照规则进行转换,再写到目的磁盘上。构建的重点是顺序,因为必然会有文件对文件的依赖,而这种依赖关系,要么像 FIS 一样预先定义,要么像 Webpack 一样自动分析,亦或像 Grunt/Gulp 一样自己定义。当然自己定义的灵活性最高,但基于有限文件选择器作为执行入口的方式,必然会无法处理未被选择的文件。
现在我们设想一种合适的工具,对以上提到的各种问题进行改进:
- 自定义处理流程和顺序;
- 允许处理遗留文件;
- 尽量减少源文件读取次数;
- 快速增量文件处理
一个典型的应用场景:
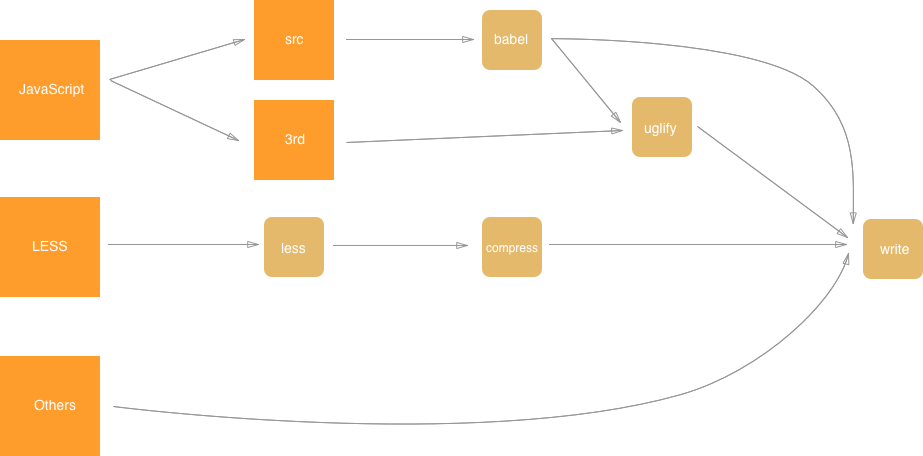
基于以上需求,我做出的一个原型工具 PantoJS。它的实现原理非常简单:基于文件选择器定义处理流,但不立即运行,在每个流上挂载多个有序的转换器(Transformer),负责转换文件的内容。在最后统一进行构建时,每个流在每个转换器上都会缓存处理后的文件内容,只要文件没有改动,该转换器后面连接的多个分支转换器都会直接从该转换器上实时获取结果,而无需再次读取文件和转换。这也就支持了增量文件后项目的快速构建。另外,多个流在读取同一个文件时是有缓存的,即只会读取磁盘一次。最后,未被选择的文件则为遗留文件,按照预定义的遗留文件规则进行处理。
PantoJS 支持文件繁殖,即一个文件在转换器上能够生成多个文件。理论上,它能够支持任意需求的构建工作,但由于缓存和流的设计,仍有以下缺陷:
- 流之间不能相互访问,而转换器允许访问原始文件,因此无能保证源文件被读取一次以内;
- 内存消耗较高(可以适当做磁盘缓存)
不过我认为这种轻量级的设计才能承担越来越繁重的前端项目构建任务。通过不断扩展转换器,其潜力非常大。