女友惨死开启的尘封孤岛疑案——读江户川乱步《孤岛之鬼》
本文整理自“莺见”微信公众号:

民主与建设出版社的江户川乱步作品我买了四本,这一次读的是单本长篇小说《孤岛之鬼》:

这部小说写于 1929-1930 年,所以还算是乱步的巅峰期作品,里面对于悬念的铺垫符合主流悬疑小说的水准。而且还融入了许多乱步的特征元素,比如同性恋、双胞胎、迷宫等等。
木崎之死
故事一开始,先铺垫了两个悬念:一是主人公“我”未到而立之年,但头发已经花白;二是“我”的妻子身上有一道巨大的伤疤。
要解释这两件匪夷所思的事情,要从“我”当年的初恋女友木崎初代说起。
“我”叫蓑浦,在 25 岁时,曾经在一家公司上班,结识了当年刚刚 18 岁的实习打字员木崎初代,后来两人逐渐发展成为男女朋友。
在交往过程中,木崎讲过她和现在的母亲并非有亲缘关系,在她儿时的记忆里,有一幅海边的画面,在半山腰上有一幢白色的大型仓库。她现在手里还有一本族谱,上面有“樋口”这个姓氏。这些都进一步补充了这篇故事的疑点。
正当二人准备订婚时,忽然半路杀出了一个“程咬金”。他叫储户道雄,忽然托人向木崎初代的母亲求亲。
令人称奇的是,“我”和储户道雄既非仇敌也非陌生人,事实上二人之前在租住地相识,成为了朋友,甚至在某种意义上来说,储户道雄对“我”的情感有些“基”的意味,不过“我”完全给拒绝了。
如今,储户道雄忽然向“我”的女友求婚,显然肯定不是巧合,很有可能是他因为嫉妒,从而有意破坏。
即便储户道雄在各方面都优于“我”,但是木崎初代并未变心,这也导致了她和她母亲之间的关系紧张。木崎初代还透露出了最近的一件怪事,就是她几次看到她家附近有一个佝偻驼背的老人。
在这之后,故事情节急转而下。虽然以上这些事件看似无关,但却出现了一件令人震惊,特别是让“我”极度悲伤的事情,那就是木崎初代在一天夜里被杀了。
头一天晚上“我”还带着木崎出去吃饭,第二天她的母亲就发现她的心脏上被插入了一把小刀。此外还遗失了木崎的薪水袋和一罐巧克力——这罐巧克力本来是前一晚“我”买给她的。

这件命案的离奇之处在于,整间房屋可以说是一间密室,所有出口都只能从内部打开,因此木崎初代的母亲自然而然成为了第一嫌疑人。
深山木幸吉
木崎死后,“我”数日未上班。等到火化那一日,“我”来到火葬场,亲眼看着她的母亲(显然已经被警察证实了清白)在捡拾骨灰残渣。“我”忽然抓起了一把灰烬,跑到旷野之处,一口吞了进去。
确实无法理解日本人的变态文化。
虽然极度悲伤,但“我”还是冷静下来,认为第一要务是找到杀害木崎的凶手,“我”想到了一个人——侦探深山木幸吉。
深山木幸吉 40 多岁,算是“我”为数不同的朋友之一。乱步对深山木幸吉的描述,大概相当于明智小五郎,只不过短命得多。
当“我”把事情的前因后果讲给他之后,随即他便要求去现场看看。在木崎的家里,“我”和深山木还遇到了一个意外的人——储户道雄,而且听人说,最近他已经来这里三次了。
在深山木探查完现场后,他给了“我”一个词:景泰蓝花瓶。这很让“我”摸不着头脑,不过他说让“我”等他五天。
既然事情已经委托给深山木了,“我”便强撑着开始上班,但是心思还是在景泰蓝花瓶这个线索上。忽然,“我”想起了与之相关的线索。木崎家的邻居就是一家二手商店,里面就陈列着两个景泰蓝花瓶。

一下班,“我”就前去询问消息,但这两个花瓶已经卖掉了,一个就是在木崎被杀的当日,另一个前两天卖掉了。通过描述人物的长相,我得知,第二个花瓶正是储户道雄买走的。
到了和深山木幸吉的约定之日,“我”来到了他家。他显得很沮丧,他说已经大概找到了木崎之死的秘密,并提到了一件极其危险的东西。他收到了一封恐吓信,让他把那件东西寄出去,否则就会在当天中午杀死他。但事实上深山木把东西寄给了“我”。
中午时分,深山木带着“我”前往海滨浴场,在沙滩上和四个不到 10 岁的小孩玩起了沙子。时间一步步靠近中午 12 点。正常来说,凶手不可能在大白天众目睽睽之下杀死一个人,但是事情就是这么发生了,过了 12 点,深山木埋在沙子下的胸口上,赫然插了一把小刀——他已经死了。

准点作案是很多侦探故事中凸显悬疑性的惯用手法。漫画柯南的故事中有许多类似的案例。
值得注意的是,在慌乱的沙滩上,“我”似乎看到了储户道雄的身影。
神秘的笔记本
之后“我”回到家里,收到了深山木幸吉生前寄给我的那件东西,原来是一件普通的石膏像,让“我”百思不得其解。之后,“我”身上发生过两件小事,一是“我”的房间似乎有人偷偷潜入并翻动过,第二是有一日“我”偶遇储户道雄从一家马戏团中走出来。
储户道雄身上有许多疑点值得“我”怀疑,他曾经多次去过木崎初代的家中,并买走了隔壁二手商店的一个花瓶。后来他还出现在深山木幸吉被杀的现场。于是,“我”决定开始接近储户。
这一天,“我”来到储户的家附近,无意中撞见了一个奇怪的人进入他家中后就不见了。那个人是一个极度驼背的老人。“我”见到储户后也没有见外,直接将心中的疑虑道了出来。
储户道雄解释他并非是杀害木崎初代或者深山木幸吉的凶手。储户由于向木崎求婚,深感对“我”有愧,因此除了医生的本职之外,他还作为一名侦探,正在调查此案。
于是,他向“我”讲述了他目前的结论,这是一个很令人震惊的推导。
他从木崎初代家的密室讲起,说到由于日本建筑的特点,邻居之间在阁楼和地板下其实是通着的,并非严格的密室。从案发当天一大早被立即买走的景泰蓝花瓶可以大胆猜测,凶手可能从二手商店潜入木崎家,作案后又返回,藏在那个花瓶中,在众目睽睽之下撤离了现场。
但是那个花瓶根本藏不下一个成年人,那凶手就有可能是一个儿童。况且,那天中午杀死深山木幸吉的现场,与之有密切接触的只有四名儿童。
凶手是儿童的推理也印证了木崎被杀现场遗失的巧克力罐子,可能是儿童受不了巧克力的诱惑。
以上说法合情合理,不过要说一名 10 岁左右的儿童藏在那个花瓶中,仍然不可能,花瓶太小了。储户听说有一种训练手法能够将儿童的身体变得异常柔软,而马戏团当中就有这样的案例。因此储户才会去马戏团打探消息,并且带走了一名这样的儿童,这时正在储户的家中受邀做客。
这名 12 岁的杂技演员叫友之助,营养不良,智力低下,沟通都有困难。不过“我”一眼就认出他就是当日在深山木幸吉旁边玩耍的四名儿童之一。储户利用巧克力引诱他,证实了他确实有能力藏在那个景泰蓝花瓶中,而且还套出了他杀害木崎初代和深山木幸吉的隐情。
友之助还提到了一个叫做“阿爸”的人,他非常害怕他。正当二人想进一步询问关于这个“阿爸”的事情时,一声巨响,友之助应声倒地而亡——有人开枪杀死了他!
“我”自然而然想到了不久前看到的那位步履蹒跚的驼背老人,不过即便警察来了,也没有找到关于凶手的任何线索。
之后“我”与储户的交谈中提到了深山木寄给“我”的那件神秘东西,二人研究一通后,发现石膏像本身没有任何意义,有用的东西藏在了它的内部。
储户打碎了石膏像,果然有东西,一件是之前木崎初代的族谱,另一件是一个记事本。

在族谱中,二人发现了一段似乎是藏宝谜语的文字,很有可能有人为了宝藏不惜各种手段来拿到这本族谱,不过一而再再而三地扑了个空。
至于那本笔记本,则承载了一个离奇的故事。写笔记的似乎是一个叫做小秀的女孩子,根据她的描述,她从小就被关在一间不大的仓房内,与她打交道的都是各种残疾人。她没有受到正规教育,只能通过三本书来学习知识。她所居住的地方,和之前木崎初代的描述很相似。
最离奇之处在于,似乎小秀与一个叫做小吉的男孩组成了连体人,他们的臀部相连。从外观上来看,他们就是一个双头八足的怪物。
小秀的笔记中透露出对外面世界的向往和对自己身世的厌恶,在最后提到了窗外有一名身穿西装的男子。
“我”和储户道雄联想到这名男子很可能就是深山木幸吉,毕竟最后就是深山木拿到了这本笔记。而且小秀在笔记中还提到了一个叫做“阿爸”的人,与友之助提到了人有相同的名字,猜测此人可能就是幕后黑手。
储户看完笔记之后,似乎受到很大的刺激,以至于立即中断了工作。翌日,“我”再次去拜访他,他向“我”讲述了另一个故事。
储户的家
原来,储户道雄生在一个奇怪的家庭,所有成员都是残疾人,父母都是面目狰狞的怪人,甚至是不是储户的亲生父母,也不得而知。
储户长大之后,提出了想去外面读书的愿望,父亲竟然满足了他,不过有几个条件,包括考上大学之前不得返家,大学要学习医学,否则就中断学费。
储户只好答应他。不单单是因为极度奇怪的家庭环境,还包括所谓母亲对其施加的不耻行径,这也是导致储户异常性取向的原因。
那本笔记本描述的环境,正是储户道雄生活了 13 年的家 !由此可知,木崎、小秀与储户一定有着紧密的家族关系。之前储户向木崎求婚,正是受到了父亲的指使,很有可能是为了族谱中的宝藏秘密。
于是,储户决定回家一趟,“我”也决定跟随。出发前发生了一段小插曲,“我”曾经把那本族谱藏在了与储户谈话那间房的房梁上,但是再找已经不见了。
二人辗转多日才抵达那个叫做“岩屋岛”的地方。在搭载二人的小船靠近小岛时,路过了一处巨大的崖边洞穴,据船主说这里有魔鬼作祟,经常有人命丧于此。

二人登岛后,看到远处有一位老人在凝视他们。以上都是伏笔。
二人顺利见到了储户的父母,果然父亲丈五郎对储户的返家进行了斥责。即便如此,二人还是在家里住下了。第二日,“我”就见到了那本笔记的作者——小秀。小秀和小吉扒在窗口,注视着“我”。只第一面,“我”就被小秀清秀的面容所吸引。几次见面后,“我”决定将其解救出来。
几日后,“我”在附近偶遇到了几天前上岸时看到的那位老人。原来他叫德叔,曾经给储户家打过工,甚至抱过小时候的储户道雄。老人透露出对储户父母的厌恶,说他们是披着人皮的恶鬼。十年前有一位据称是丈五郎兄弟的人来到这个小岛,几天后就被发现死在了那个洞窟里,怀疑就是丈五郎所为。
等到“我”再一次来到小秀被囚禁的仓库边,竟然发现里面出现了一张本不应该出现的脸——储户道雄。他通过纸条告诉“我”他已经被父亲监禁,让“我”赶紧逃出去。
“我”虽然立马回去收拾东西,但却没打算离开。丈五郎赶走“我”时,让一位仆人送走“我”。而后,那位仆人竟然将“我”交给了那位叫德叔的老人。
德叔原本就与丈五郎不合,在听到了“我”的遭遇后,便决定帮忙。他的儿子与“我”身材相仿,于是换上“我”的衣服,假装将“我”划船带走,而“我”正在德叔的屋子里远远地看着这一切。
不过,“我”却意外地看到丈五郎站在悬崖边上,看准德叔的船,将一块大石头推下。那里正是相传吃人的洞窟附近。看来,丈五郎想杀人灭口,便一石二鸟,利用洞窟的迷信故意造成意外事故,除掉了“我”,以及知道其家族秘密的德叔。
德叔父子二人的意外丧命,更加坚定了“我”要将丈五郎绳之以法的决心。好在这时候,他并不知道“我”非但没有死,而且还在岛上。
“我”白天潜伏在德叔的小屋里(丈五郎竟然没有来探查,至少应该知道德叔的儿子还在这里),晚上偷偷溜出去。有一次,“我”偶然发现丈五郎在房顶揭开了几片瓦片,联想到丈五郎大概率已经拿到了那本族谱,也许已经破译了上面的藏宝密码,他可能正在寻宝。
“我”悄悄地与被囚禁中的储户取得了联系,并告知了丈五郎谋害德叔父子的事情。储户很纠结,虽然丈五郎是他的父亲,但是也不能够容忍如此恶劣行径。最后还是决定,与“我”共同策划对丈五郎一家进行反击。
机会来了,几位身强力壮的仆人出岛好几天,剩下的都是老弱病残。二人轻而易举就“造反”成功,丈五郎夫妇被关了起来,几位残疾人,包括小秀和小吉都被释放了出来,显得异常兴奋。
深入险境
接下来,“我”和储户开始了寻宝活动。根据族谱上的谜语,几经曲折后最终将宝藏位置定位到一口枯井。
枯井侧壁有一个洞口,二人准备了蜡烛绳索一类的工具,钻了进去。这是一处天然洞穴,内部岔路极多,二人不得不用绳子来记录来时的路线,以免迷路。

不过,很快他们就被困了,因为发现绳子松松垮垮的——有人在上面把绳子剪断了!好熟悉的味道,从现在开始,悬疑小说已经开始有了探险的味道。
而这时,二人发现了一个更加棘手和致命的问题,那就是洞中出现了水——洞穴和海水是相连的,而且似乎水位在不断地上涨,这说明外面涨潮了!
海水很快把所有的退路都堵死了,二人被困在了一处气穴中。水慢慢地涨到了他们的脖颈处,就在他们等死之际,发现水不再上涨,这说明残存的空气顶住了水压。不久后,随着潮水退去,水位开始下降,二人终于松了一口气。
不过,刚才的潮水把二人身上的所有引火之物都打湿了,现在他们只能身处漆黑之中不断摸索。
他们尝试一种贴边走的方法,大概原理是。无论洞穴岔路多么复杂,只要有洞口,一侧洞壁就不能形成一个闭环。那么只要一直触摸一侧的墙壁,即便会走很多冤枉路,最终仍然会经过出口处。
不过,尝试了几次,储户发现并不奏效,每隔一段时间总会触摸到相似的墙壁,这说明他们一直在绕圈子。二人已经无力在探索了,只好坐下来等待宿命的安排。
就在这时,储户听到了什么声音,一喊之下,竟然有人声回应。经过确认,竟然是德叔!
德叔不是被丈五郎推下的石块砸死了吗?原来船翻了之后,德叔没有死,而是奋力游上了岸,进入了那个传说吃人的洞窟,一路到此。
原来,这口枯井之下竟然连通着那个可怕的崖边洞窟。德叔还教二人吃螃蟹充饥——洞穴里到处都是从海里爬上来的螃蟹。
有东西吃就有力量,这样才能保存逃生的体力。在这个间隙,德叔道出了一个尘封的故事。
原来,丈五郎的家原先属于樋口一家,主人叫万兵卫。在 1866 年,他和一个丑陋的残疾女佣生了一个儿子,叫海二,也是一个丑陋的驼子。母子二人被赶了出去。
1877 年,万兵卫与正室妻子的孩子春雄,迎娶了岛外的姑娘琴平梅野。
1879 年,春雄和梅野生下了女儿春代,很快春雄病逝。
1887 年,海二以储户丈五郎之名返回岛上,霸占了樋口的家。梅野带着春代逃回了娘家。
1890 年,丈五郎找了一个丑陋的驼子女人结婚。
1892 年,丈五郎夫妻生下了一个孩子,也是一个驼子。同年,他不知从哪里拐来了道雄。
1900 年,春代结婚。
1905 年,春代生下大女儿初代,即之后的木崎初代。
1907 年,春代生下了二女儿阿绿。同年她的丈夫去世。春代无依无靠,只能跟着母亲梅野的关系回到了岩屋岛,借住在丈五郎家中。这就是木崎初代回忆中经常提到的画面,即在海边照看一个婴孩——正是她的妹妹阿绿。
1908 年,春代带着初代出逃,但是阿绿没有带走。
后来,春代来到大阪,由于无力抚养而抛弃了初代,她被木崎夫妻领养而去。但阿绿却寄养在了丈五郎家中。
可见,初代是樋口家的正统继承人。她之前所持有的家族谱正是她自己的。
但阿绿呢?其实阿绿就是小秀。因为丈五郎记恨正常人,因此才各种尝试制造出残疾人。他把阿绿和小吉以外科手术的方式连接到了一起,这是何等地变态!
而丈五郎当年想资助储户去学习医学,并非出于善意,而是想利用他制造更多残疾人。
逃生出天
了解完整件事情的来龙去脉之后,三人开始了逃生。很快,他们就找到了被剪断的绳子,并且意外地听到了丈五郎在唱歌。
原来,丈五郎不知怎么从被监禁的房间里逃了出来。并且顺藤摸瓜找到了这口枯井。他剪断了绳子,意图让储户和“我”困死在地下世界。
然后,阴差阳错,丈五郎找到了那笔宝藏,他此时正站在宝藏上唱歌,浑然不理在场的其他人——宝藏让他发疯了。

这之后,在储户的提醒下,“我”发现自己的头发已经花白了。原来是底下世界的一遭,让“我”在一夜之间愁白了头,这也呼应了本故事一开始的一处铺垫。
最终的结局是,储户将阿绿(也就是小秀)和小吉分开了。“我”娶了阿绿,这也解释了故事一开头为什么“我”妻子身上有一道伤疤。阿绿继承了那一笔宝藏,“我”用那一笔钱盖了一间宅院,用于收养那些残疾人。还盖了一间整形外科医院,竭尽全力帮助残疾人恢复正常生活。
“我”还把初代的养母接了过来养老。虽然初代已死,但是她的亲妹妹继续充当着她原本的角色。
后来,正当“我”想邀请储户来做外科医院的院长时,他却忽然病逝。好在在这之前,他已经找到了他的亲生父母。
至于当初深山木幸吉为什么能找到岩屋岛,带回阿绿的笔记,那是因为他曾经认识过春代,也就是阿绿和初代的母亲。
总结
《孤岛之鬼》这篇故事中的悬念设定技巧,即便放在今天也不过时。其中对人物的刻画也足够让人印象深刻。储户对“我”来说,是亲密的朋友,但也包含着异于常人的情感因素。丈五郎的一生是悲剧的,他虽然做出如此有悖伦理的恶行,但他同时也是一名因天生身体残缺而被歧视的受害者。
这篇 16.5 万字的小说很适合来改编成电影,里面包含了足够多的引人入胜的悬念。最后,我来画一张能描绘故事中人物关系的图谱:
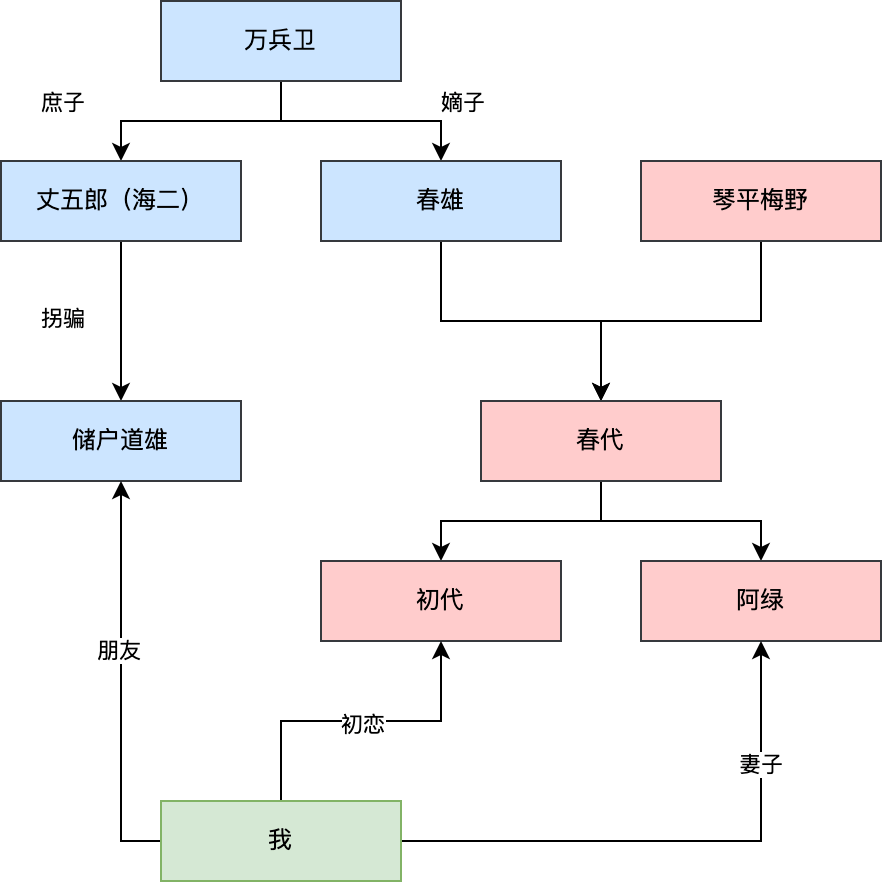
(文中大部分图片采用 AI 生成)











































































